AWS S3 Files revoluciona la interacción con S3, permitiendo acceder a buckets como sistemas de archivos POSIX de alto rendimiento. Esto simplifica migraciones de apps legadas, mejora el intercambio de datos y ofrece un rendimiento superior con la escalabilidad y eficiencia de costos de S3. Descubre cómo aprovechar este cambio radical para tu arquitectura.
¿Necesitas algo así para tu negocio?
Construimos tu landing page con buen SEO, diseño moderno y todo incluido desde $100/mes.
En el panorama cambiante de la infraestructura en la nube, Amazon S3 ha sido durante mucho tiempo el estándar de oro para el almacenamiento de objetos escalable, duradero y rentable. Sin embargo, a pesar de todo su poder, el paradigma de almacenamiento de objetos presenta un desafío único para las aplicaciones diseñadas para interactuar con sistemas de archivos tradicionales. Esta falta de concordancia a menudo lleva a capas de acceso a datos complejas, cuellos de botella de rendimiento o migraciones costosas a otros servicios de almacenamiento. Pero, ¿y si pudieras tener lo mejor de ambos mundos? ¿Qué pasaría si tus buckets de S3 pudieran comportarse como un sistema de archivos de alto rendimiento y compatible con POSIX?
Aquí es donde entra en juego AWS S3 Files. Este innovador anuncio de AWS cambia fundamentalmente la forma en que las empresas pueden aprovechar sus datos de S3, cerrando la brecha entre la escala y la durabilidad del almacenamiento de objetos y los requisitos interactivos de baja latencia de las aplicaciones basadas en archivos. Para los CTO, líderes técnicos y fundadores de startups, esto no es solo un servicio más; es un habilitador estratégico que puede desbloquear nuevas eficiencias, simplificar la arquitectura y mejorar significativamente el rendimiento de las cargas de trabajo intensivas en datos.
Qué Cambió: Uniendo el Almacenamiento de Objetos y los Sistemas de Archivos
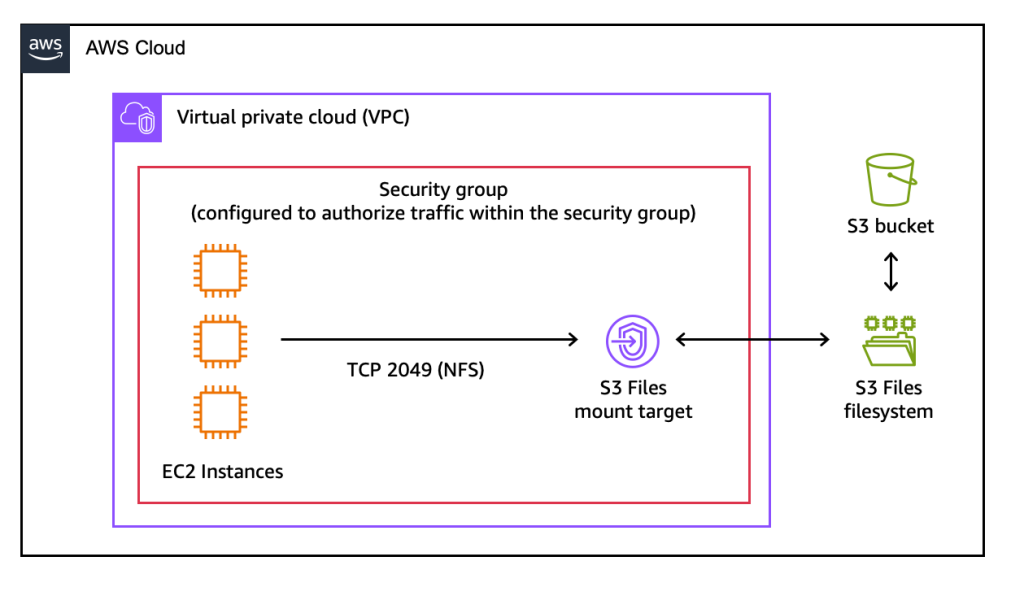
AWS S3 Files transforma la forma en que sus recursos informáticos interactúan con S3. Tradicionalmente, las aplicaciones que necesitaban semántica de sistema de archivos utilizaban servicios como Amazon EFS o Amazon FSx, o construían capas personalizadas complejas sobre la API de objetos de S3. Aunque efectivos, estos enfoques implicaban costos más altos para el almacenamiento sin procesar, limitaciones regionales o la sobrecarga de un desarrollo a medida.
Con AWS S3 Files, los buckets de S3 ahora se pueden montar directamente como sistemas de archivos de alto rendimiento en recursos informáticos de AWS como instancias EC2, tareas ECS y pods EKS. La innovación central radica en su capacidad para ofrecer un rendimiento de sistema de archivos casi nativo, con latencias de ~1 ms para operaciones de archivo comunes. Esto se logra a través de un cliente optimizado y una infraestructura subyacente de AWS que gestiona de manera inteligente el acceso a datos y el almacenamiento en caché, asegurando que sus aplicaciones perciban S3 como un sistema de archivos local y altamente receptivo.
Los puntos técnicos clave incluyen:
- Compatibilidad POSIX: Admite operaciones estándar de sistema de archivos como crear, leer, escribir, añadir, truncar, renombrar, listar directorios y gestionar permisos.
- Alto Rendimiento: Alcanza latencias de sub-milisegundos para datos de acceso frecuente, mejorando drásticamente la capacidad de respuesta de las aplicaciones interactivas.
- Compartición de Datos Sin Interrupciones: Múltiples instancias de computación pueden montar el mismo sistema S3 Files, lo que permite una compartición de datos simplificada sin una coordinación compleja.
- Rentabilidad: Aprovecha la eficiencia de costos y la durabilidad inigualables de Amazon S3 para el almacenamiento de datos subyacente.
- Escalabilidad: Hereda la enorme escalabilidad de S3, lo que le permite almacenar y acceder a petabytes de datos sin gestionar la capacidad del sistema de archivos.
Esto significa que ya no tiene que comprometerse entre los beneficios del almacenamiento de objetos (costo, escala, durabilidad) y la necesidad de capacidades de archivo interactivas. S3 Files está diseñado para hacer que el acceso a datos sea intuitivo y de alto rendimiento para una amplia gama de aplicaciones, desde sistemas heredados hasta cargas de trabajo modernas de IA/ML.
Tutorial Paso a Paso: Montar y Usar AWS S3 Files
Recorramos cómo configurar e interactuar con AWS S3 Files en una instancia de Amazon EC2. Para este tutorial, asumiremos que tienes una cuenta de AWS activa, un bucket de S3 configurado y una instancia EC2 ejecutando Amazon Linux 2023.
Requisitos Previos:
- Una cuenta de AWS con acceso administrativo o un usuario de IAM con permisos para crear y gestionar instancias EC2, buckets de S3 y recursos de S3 Files.
- Un bucket de Amazon S3 existente (por ejemplo,
your-unique-s3-bucket-name) en su región de AWS deseada (por ejemplo,us-east-1). - Una instancia de Amazon EC2 (por ejemplo,
t3.medium) ejecutando Amazon Linux 2023, con reglas de grupo de seguridad apropiadas para permitir el acceso SSH. Asegúrate de que el rol de IAM de la instancia EC2 tenga permisos para acceder a tu bucket de S3 (s3:GetObject,s3:PutObject,s3:ListBucket) y a las operaciones de S3 Files (s3-files:*).
Instalación y Configuración:
Primero, accede por SSH a tu instancia EC2. Instalaremos el cliente de S3 Files necesario. Para este ejemplo, asumiremos que una utilidad de cliente dedicada está disponible a través del administrador de paquetes.
# Actualiza los paquetes de tu sistema
sudo yum update -y
# Instala el cliente de AWS S3 Files (nombre de paquete hipotético para demostración)
sudo yum install -y aws-s3-files-client
# Verifica la instalación
s3-files --version
A continuación, necesitamos crear un punto de montaje en tu instancia EC2 donde el bucket de S3 será accesible como un sistema de archivos, y luego realizar la operación de montaje.
# Crea un directorio para que sirva como punto de montaje
sudo mkdir /mnt/s3data
# Monta tu bucket de S3 usando el comando s3-files
# Reemplaza 'your-unique-s3-bucket-name' con el nombre real de tu bucket de S3
# Reemplaza 'us-east-1' con la región de tu bucket
# Asegúrate de que el rol de IAM de tu instancia EC2 tenga los permisos S3 y S3-Files necesarios
sudo s3-files mount s3://your-unique-s3-bucket-name /mnt/s3data --region us-east-1
# Verifica el montaje
df -h /mnt/s3data
Si el comando se ejecuta correctamente, deberías ver tu sistema de archivos S3 Files listado en la salida de df -h, mostrando típicamente una gran capacidad que refleja el bucket de S3 subyacente. Tu bucket de S3 ahora es accesible a través de operaciones estándar de sistema de archivos en /mnt/s3data.
Interactuando con S3 Files usando Python:
Ahora que el bucket de S3 está montado, puedes interactuar con él usando comandos estándar de sistema de archivos y APIs de lenguajes de programación. Demostremos operaciones de archivo comunes usando un script de Python.
import os
mount_path = "/mnt/s3data"
file_name = "demo_file.txt"
file_path = os.path.join(mount_path, file_name)
directory_name = "my_directory"
directory_path = os.path.join(mount_path, directory_name)
# --- Operaciones de Archivos ---
# 1. Crear y escribir en un nuevo archivo
print(f"[INFO] Creando y escribiendo en: {file_path}")
with open(file_path, "w") as f:
f.write("¡Hola desde AWS S3 Files!\n")
f.write("Esta es una demostración de acceso POSIX.\n")
print("[ÉXITO] Archivo escrito.")
# 2. Leer el contenido del archivo
print(f"\n[INFO] Leyendo de: {file_path}")
with open(file_path, "r") as f:
content = f.read()
print("Contenido de demo_file.txt:")
print(content)
print("[ÉXITO] Archivo leído.")
# 3. Añadir contenido al archivo
print(f"\n[INFO] Añadiendo a: {file_path}")
with open(file_path, "a") as f:
f.write("Añadiendo una nueva línea con S3 Files.\n")
print("[ÉXITO] Contenido añadido.")
# 4. Leer de nuevo para ver el contenido añadido
print(f"\n[INFO] Leyendo archivo actualizado: {file_path}")
with open(file_path, "r") as f:
content = f.read()
print("Contenido actualizado de demo_file.txt:")
print(content)
print("[ÉXITO] Archivo actualizado leído.")
# --- Operaciones de Directorio ---
# 5. Crear un nuevo directorio
print(f"\n[INFO] Creando directorio: {directory_path}")
os.makedirs(directory_path, exist_ok=True)
print("[ÉXITO] Directorio creado.")
# 6. Listar el contenido del punto de montaje
print(f"\n[INFO] Listando contenido de {mount_path}:")
for item in os.listdir(mount_path):
print(f" - {item}")
print("[ÉXITO] Directorio listado.")
# --- Limpieza (Opcional) ---
# Descomenta las líneas de abajo si deseas eliminar los archivos/directorios creados
# print(f"\n[INFO] Limpiando: {file_path} y {directory_path}")
# os.remove(file_path)
# os.rmdir(directory_path) # Solo funciona si el directorio está vacío
# print("[ÉXITO] Limpieza completada.")
Guarda este script como s3_files_demo.py en tu instancia EC2 y ejecútalo usando python3 s3_files_demo.py. Observarás la salida estándar del sistema de archivos, demostrando la integración perfecta de S3 Files.
Problemas Comunes y Solución de Problemas:
- Permisos de IAM: Asegúrate de que el rol de IAM de tu instancia EC2 tenga permisos tanto
s3:*(para tu bucket específico) comos3-files:*. Este es el problema más común. - Discrepancia de Región: La
--regionespecificada durante el montaje debe coincidir con la región de tu bucket de S3. - Versión del Cliente: Mantén tu
aws-s3-files-clientactualizado para asegurar la compatibilidad y el acceso a las últimas características y mejoras de rendimiento. - Desmontaje: Para desmontar de forma segura, usa
sudo umount /mnt/s3data. - Concurrencia y Consistencia: Si bien S3 Files proporciona semántica POSIX, recuerda que el almacenamiento subyacente es S3, que tiene consistencia eventual para algunas operaciones. Para escrituras de una sola instancia, esto generalmente está bien, pero las escrituras distribuidas complejas aún podrían requerir un diseño de aplicación cuidadoso.
Caso de Uso Real: Modernizando Aplicaciones Heredadas con Acceso a Datos de Alto Rendimiento
Imagina un escenario en el que una aplicación heredada local depende en gran medida de un sistema de archivos de red (NFS) compartido para almacenar y procesar grandes volúmenes de datos, quizás para procesamiento por lotes, análisis o renderizado de medios. Migrar esta aplicación a la nube presenta tradicionalmente un dilema: refactorizar la aplicación para usar la API de objetos de S3 (costoso, lento) o implementar un sistema de archivos administrado como EFS o FSx (potencialmente mayor sobrecarga operativa y costo por GB en comparación con S3).
Con AWS S3 Files, esta migración se vuelve drásticamente más simple y rentable. Puedes trasladar la aplicación heredada a instancias EC2, montar un bucket de S3 a través de S3 Files, y la aplicación interactuará con S3 como si fuera un recurso compartido NFS local. Este enfoque conserva la lógica de sistema de archivos existente de la aplicación, elimina la necesidad de una refactorización extensa y se beneficia inmediatamente de la escalabilidad, durabilidad y el perfil de costos de S3. Los datos para análisis o cargas de trabajo de IA/ML pueden almacenarse directamente en S3 y procesarse mediante clústeres de cómputo (por ejemplo, EKS) que montan el sistema S3 Files, logrando un acceso de alto rendimiento sin duplicación de datos o capas de sincronización complejas. Esta capacidad se traduce directamente en una adopción más rápida de la nube y un retorno de la inversión más rápido para las iniciativas de modernización.
Comparación: S3 Files vs. Otras Opciones de Almacenamiento de AWS
AWS ofrece una rica cartera de servicios de almacenamiento, cada uno optimizado para diferentes casos de uso. Comprender dónde encaja S3 Files puede ayudarte a tomar decisiones arquitectónicas informadas:
- API de Objetos Nativos de S3: Proporciona el menor costo y la mayor escala, pero requiere que las aplicaciones se diseñen en torno a la semántica de almacenamiento de objetos (HTTP PUT/GET). S3 Files abstrae esta complejidad, ofreciendo acceso al sistema de archivos sin refactorización.
- Amazon EFS (Elastic File System): Un sistema de archivos NFS totalmente administrado para EC2. EFS es más sencillo de configurar para necesidades generales de NFS, pero puede tener costos por GB y latencia más altos para requisitos de rendimiento extremadamente altos o escala global en comparación con S3, especialmente para datos fríos. S3 Files ofrece los beneficios de costos de S3 con acceso al sistema de archivos.
- Amazon FSx (File System for Lustre, OpenZFS, NetApp ONTAP, Windows File Server): Sistemas de archivos administrados especializados y de alto rendimiento optimizados para cargas de trabajo específicas (por ejemplo, HPC con Lustre, servidores de archivos empresariales). Si bien ofrecen un rendimiento superior para su nicho, a menudo conllevan costos más altos y más sobrecarga de administración que S3 Files para el acceso general a archivos de datos de S3. S3 Files es ideal cuando se necesita la escala y el costo de S3 con una sólida semántica POSIX, en lugar de un sistema de archivos especializado.
S3 Files no es un reemplazo para estos servicios, sino un complemento potente, particularmente cuando se necesita combinar las ventajas económicas y de durabilidad de S3 con patrones de acceso a sistemas de archivos tradicionales y un rendimiento de baja latencia en cómputo de AWS.
Preguntas Frecuentes
¿Necesitas ayuda para implementar esto? Contacta a We Do IT With AI para obtener orientación experta.
¿Listo para tu sitio web profesional?
Diseño moderno, SEO bien hecho, hosting + base de datos + mantenimiento — todo incluido desde $100/mes. Respondemos por WhatsApp en menos de 1 hora.
Fuente original
aws.amazon.comRecibe las mejores guias de tecnologia
Tutoriales, herramientas nuevas y tendencias de IA directo en tu correo. Sin spam, solo contenido de valor.
Puedes desuscribirte en cualquier momento.
